Bikes


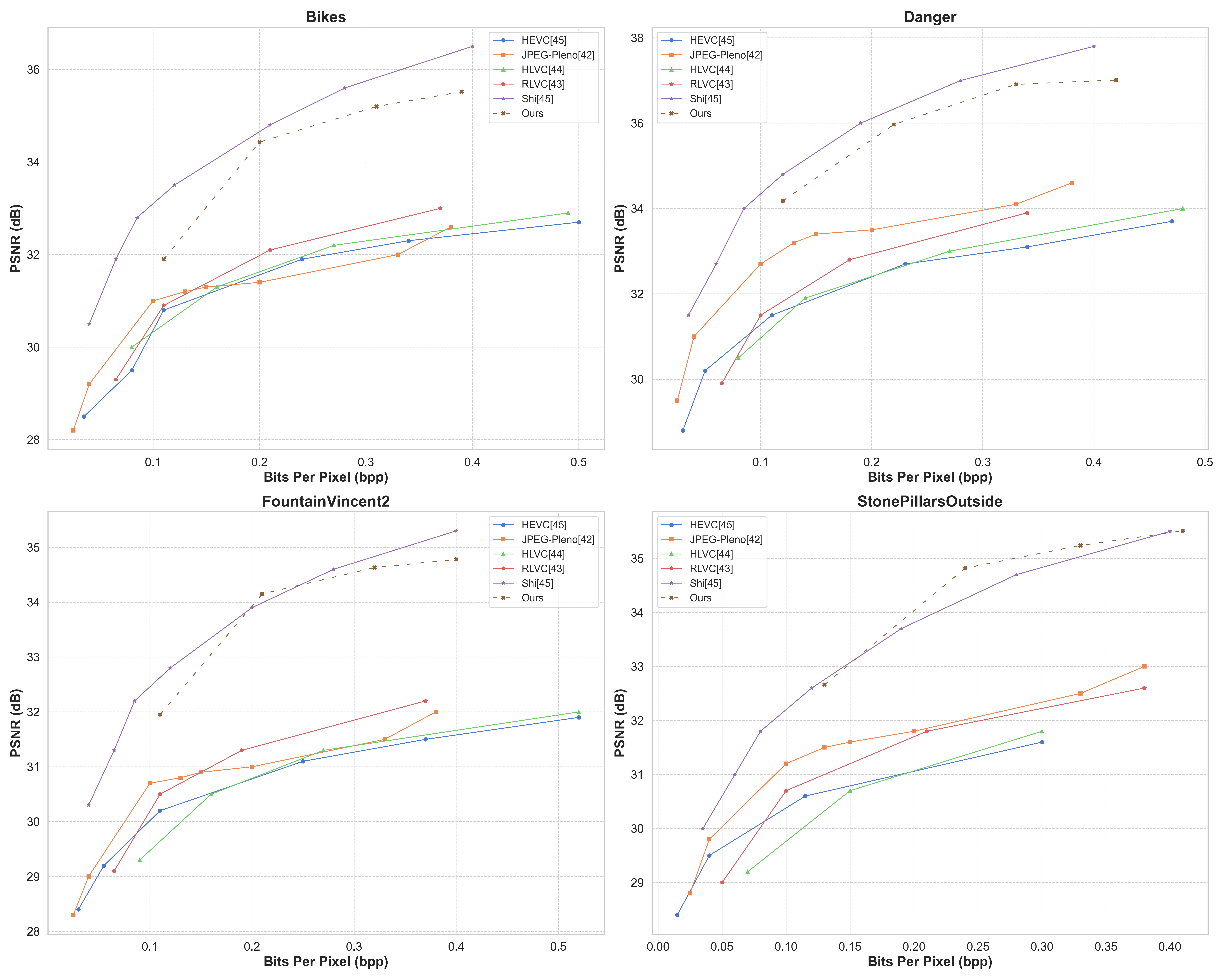
Light field (LF) imaging captures both spatial and angular information, which is essential for applications such as depth estimation, view synthesis, and post-capture refocusing. However, the efficient processing of this data, particularly in terms of compression and execution speed, presents challenges. We propose a Variational Autoencoder (VAE)-based framework to disentangle the spatial and angular features of light field images, focusing on fast and efficient compression. Our method uses two separate sub-encoders—one for spatial and one for angular features—to allow for independent processing in the latent space, which facilitates more streamlined processing. Evaluations on standard light field datasets show that our approach reduces execution time significantly, with a slight trade-off in Rate-Distortion (RD) performance, making it suitable for real-time applications. This framework also supports enhancements in other light field processing tasks, such as view synthesis, scene reconstruction, and super-resolution.
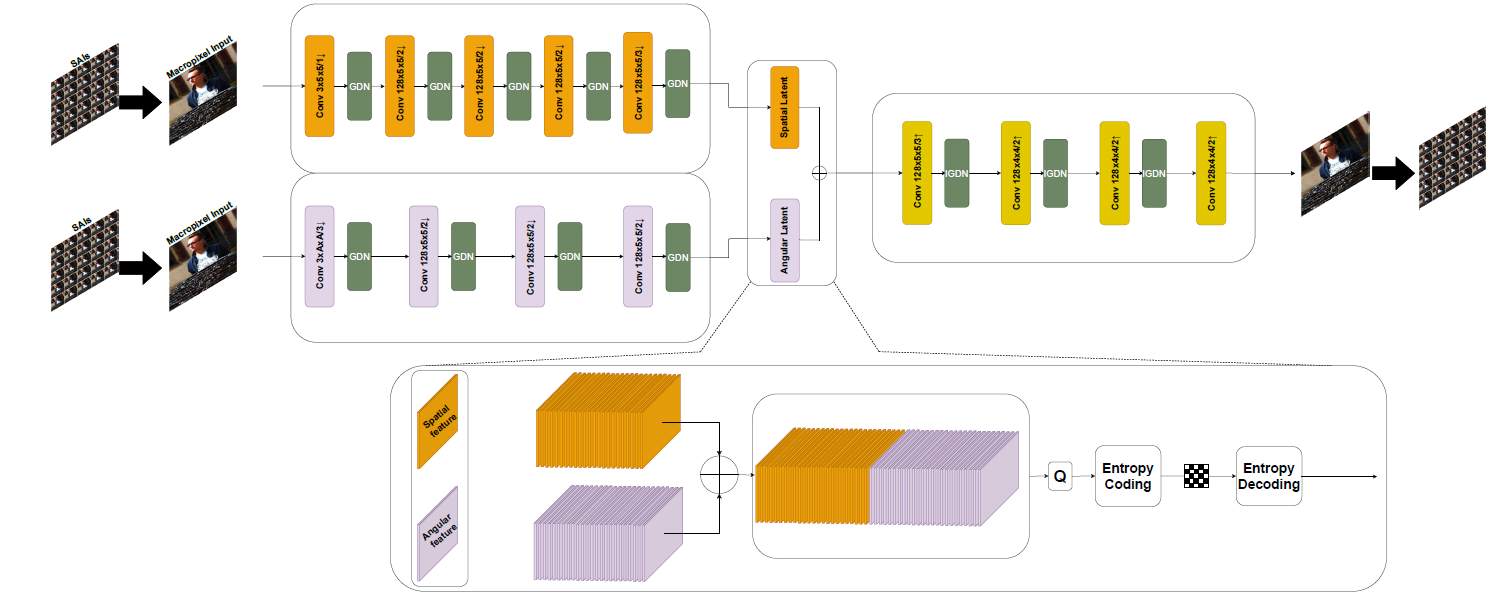
Rate-Distortion (RD) curve comparing the performance of our proposed VAE-based light field compression method against HEVC, RLVC, HLVC, JPEG-Pleno, and Shi’s method . Our method consistently outperforms the others across most datasets in terms of compression efficiency and image reconstruction quality, except for Shi’s method, which shows superior results on a few specific datasets.
Comparison of the Encoding and Decoding time for our method VS RLVC, HLVC, Jpeg-Pleno and Shi's
Bikes
Danger


Fountain


Pillars


Jpeg-Pleno
Ours
RLVC






@ARTICLE{10849543,
author={Takhtardeshir, Soheib and Olsson, Roger and Guillemot, Christine and Sjöström, Mårten},
journal={IEEE Access},
title={Efficient and Fast Light Field Compression via VAE-Based Spatial and Angular Disentanglement},
year={2025},
volume={13},
number={},
pages={18594-18607},
keywords={Light fields;Image coding;Decoding;Kernel;Image reconstruction;Feature extraction;Training;Imaging;Streaming media;Redundancy;Light field;compression;disentangling;variational auto-encoder},
doi={10.1109/ACCESS.2025.3532608}}